
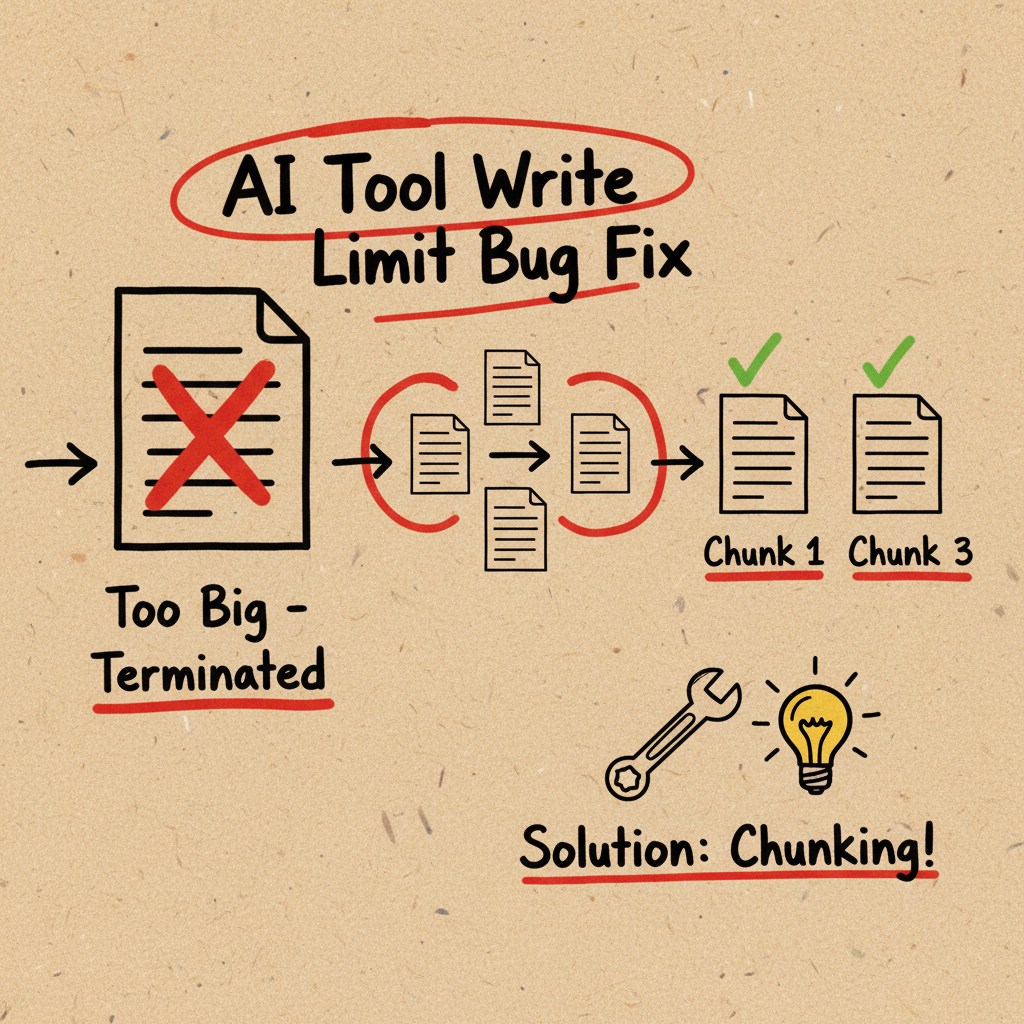
今天在用 OpenClaw 跑公众号文章自动化 pipeline 的时候,发现一个坑:每次跑到 Step 4(初稿撰写)就被 terminated。
问题现象
公众号文章 pipeline 有 9 个步骤,前 3 步(选题、素材、大纲)都正常,但到 Step 4 写初稿时,agent 直接被 terminated,没有任何错误信息。
Step 4 的任务是根据大纲和素材写一篇 2000-4000 字的中文文章,然后用 write 工具一次性写入文件。
根因分析
OpenClaw 的 write 工具在底层调用 LLM 的 tool call 能力。当你让 agent 一次性生成并写入一篇 3000+ 字的中文文章时,tool call 的输出 token 量会非常大。
这会触发模型的单次输出 token 上限,导致响应被截断,agent 进程直接 terminated——不是报错,是直接挂掉。
关键点:这不是 write 工具本身的 bug,而是 LLM 单次输出 token 的硬限制。中文文章尤其容易触发,因为中文的 token 效率比英文低(同样字数消耗更多 token)。
解决方案:分块写入
核心思路很简单——化整为零。把一次大输出拆成 2-3 次小输出:
- 第 1 次:用
write创建文件,写入前 1/3(开头到第一个大段落) - 第 2 次:用
edit在文件末尾追加中间部分 - 第 3 次:用
edit在文件末尾追加结尾部分 - 每次写入控制在 1500 字以内
具体改动
在 SKILL.md 的 pipeline 定义中,给所有输出长文章的步骤加上分块写入指令:
- Step 4 初稿撰写 — 文章必须分 2-3 次写入文件
- Step 5 润色优化 — 同样分块写入
- 搬运模式 R2 改写 — 同样分块写入
这样 agent 在执行时,每次 tool call 的输出量都在安全范围内,不会触发 token 上限。
经验总结
- 任何需要一次性输出超过 1500 字中文的 tool call,都应该拆分
write创建文件 +edit追加内容,是最稳的分块写入模式- 这个问题在英文场景下不太容易触发(token 效率更高),但中文场景下是高频坑
- 如果你在用 OpenClaw 做内容自动化,建议在 skill 定义里就把分块写入写死,别指望 agent 自己判断
适用范围
这个问题不只是公众号文章 pipeline 会遇到。任何让 AI agent 通过 tool call 一次性写入大量内容的场景都可能触发:
- 生成长篇文档
- 写完整的代码文件
- 生成报告或分析
- 批量数据处理结果写入
解决方案都一样:分块。

Member discussion: