
最近在疯狂调研论文,发现一个有趣的现象:无论是 Claude、GPT 还是 Gemini,它们内置的搜索工具在结果广度上似乎都不如 Grok,而且 Grok 搜索速度还巨快。然而 Grok 又不如 Claude 讲得好。
于是一个自然的想法诞生了:让 Grok 负责搜索找信源,Claude 负责阅读信源并总结回答,各司其职,岂不美哉?
这就是 GrokSearch MCP 的核心思路。
为什么需要这个组合?
在实际使用中,我发现了几个痛点:
1. Claude 内置搜索的广度有限,尤其在学术论文和技术文档场景下,经常搜不到最新的内容
2. Grok 搜索又快又广,但让它 fetch 网页内容时总是或漏或省,对论文阅读这种需要完整信息的任务完全不能接受
3. fetch 网页内容本质上是一个工程问题——把网页转换成格式化文档,不需要什么"智能",让专业工具来做就好
经过多方比对,最终选择了 Tavily 作为 fetch 工具。它提供的 extract 和 map 功能天然支持 agentic crawl 能力,抓取质量稳定可靠。
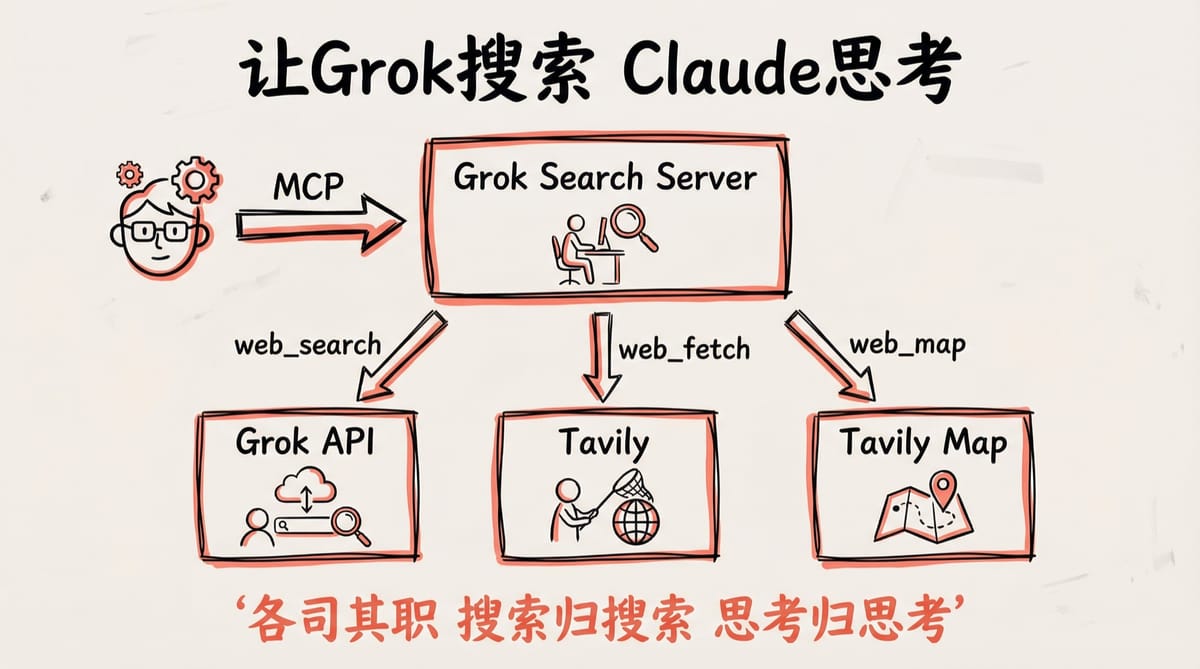
架构设计
整体架构非常清晰,通过 MCP 协议将三个能力组合在一起:
Claude ──MCP──► Grok Search Server
├─ web_search ───► Grok API(AI 搜索)
├─ web_fetch ───► Tavily Extract(内容抓取)
└─ web_map ───► Tavily Map(站点映射)
每个组件做自己最擅长的事:
- Grok:搜索广度大、速度快,负责找到最相关的信源
- Tavily:专业的网页内容提取,完整、准确、不遗漏
- Claude:强大的理解和总结能力,负责阅读信源并给出高质量回答
实际效果对比
以 Claude Opus 4.6 为例,在相同的实验条件下:
不开 GrokSearch MCP:即使打开了 Claude 内置搜索工具,Opus 4.6 仍然倾向于相信自己的内部知识,不主动查询官方文档获取最新示例。这在技术文档快速迭代的场景下很容易产生幻觉。
开启 GrokSearch MCP:Opus 4.6 会主动调用多次搜索获取官方文档,回答更加可靠,引用的代码示例也是最新版本。
差异非常明显——有了外部搜索加持,大模型的幻觉率显著降低。
安装配置
安装非常简单,一条命令搞定:
claude mcp add-json grok-search --scope user '{
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"git+https://github.com/GuDaStudio/GrokSearch@grok-with-tavily",
"grok-search"
],
"env": {
"GROK_API_URL": "https://your-api-endpoint.com/v1",
"GROK_API_KEY": "your-grok-api-key",
"TAVILY_API_KEY": "tvly-your-tavily-key",
"TAVILY_API_URL": "https://api.tavily.com"
}
}'需要准备两个 API Key:
- Grok API Key:从 console.x.ai 获取,支持 OpenAI 兼容格式的中转站也可以
- Tavily API Key:从 tavily.com 注册获取,免费 Researcher 计划每月 1000 credits
安装后验证:
claude mcp list显示 grok-search 连接成功即可。
进阶技巧:禁用内置搜索
强烈推荐在 Claude 对话中输入:
调用 grok-search toggle_builtin_tools,关闭 Claude Code 内置的 WebSearch 和 WebFetch这会自动修改项目级 .claude/settings.json 的 permissions.deny,强制 Claude Code 只使用 GrokSearch MCP 进行搜索。这样可以确保每次搜索都走 Grok,获得更广泛的搜索结果。
Codex 配置
如果你在用 OpenAI Codex,也可以配置:
[mcp_servers.grok-search]
command = "uvx"
args = [
"--from",
"git+https://github.com/GuDaStudio/GrokSearch@grok-with-tavily",
"grok-search"
]
[mcp_servers.grok-search.env]
GROK_API_URL = "https://your-api-endpoint.com/v1"
GROK_API_KEY = "your-grok-api-key"
TAVILY_API_URL = "https://api.tavily.com"
TAVILY_API_KEY = "tvly-your-tavily-key"Codex 本身很擅长遍历项目代码,基本不存在代码幻觉,但缺少外部知识时会疯狂自己试错。配合 GrokSearch 后,它能主动搜索 GitHub Issues 和官方文档中已有的解决方案,大幅减少无效尝试。
我的使用体验
实际配置使用了一段时间,几点感受:
1. 搜索质量确实提升明显——Grok 的搜索广度比 Claude 内置的好不少,尤其是技术类内容
2. Tavily 的 fetch 非常稳定——不会像让大模型 fetch 那样丢三落四,内容完整度很高
3. 组合使用体验清爽——各司其职,搜索归搜索,抓取归抓取,总结归总结
4. 成本可控——Grok 4.1 Fast 价格很低($0.20/M input),Tavily 免费额度够日常使用
如果你也在用 Claude Code 或 Codex 做技术研究,强烈推荐试试这个组合。
相关链接
- GrokSearch 项目:https://github.com/GuDaStudio/GrokSearch
- Tavily:https://tavily.com
- xAI Console:https://console.x.ai

Member discussion: